
.svg)
The Architecture Behind AI That Actually Works
Everyone's posting about shipping apps with AI. Not enough people are posting about the architectural decisions that determine whether those apps hold up in production.
I built an AI-powered research and accountability platform over the last few weeks. Not a chatbot. Not a wrapper around a Claude subscription. A multi-pass pipeline with identity disambiguation, organizational intelligence, confidence tiering, vector deduplication, model tiering, graceful degradation, and source attribution on every single fact it produces. I designed the architecture, the data models, and the decision framework. Cursor wrote the code. Every LLM call is traced and auditable in Langfuse. Every fact has a source URL. Every confidence score has math behind it, not vibes.
This post is about the decisions I made and why they matter more than the tools I used to implement them.
What it does
USDWatch is a case intelligence platform. You give it a person or an organization. It searches the open web, scrapes relevant sites, pulls public records, board minutes, policy documents, incident reports. It builds verified profiles of the people involved, maps the organizational and regulatory graph around them, and finds the contradictions between what you were told and what the records actually say.
For people, it produces a "battle card": a sourced profile with public statements, voting records, organizational ties, and concrete action items.
For organizations, it runs a five-phase intelligence pipeline: it crawls the entity's website, searches news coverage, listens for social media complaints, maps the oversight and regulatory chain above them, and checks for existing public records requests. It discovers who regulates whom, who funds whom, who leases to whom, and builds a navigable graph of those relationships. Every entity it discovers becomes a clickable node that you can research further.
It analyzes the gaps in your evidence and generates public records request letters targeting exactly what's missing. When those records come back, you upload them. The system parses, chunks, and vector-indexes the new documents, then re-analyzes your case with the new data folded in. New contradictions, new leverage.
It's a feedback loop: research, identify gaps, request records, ingest responses, refine. It hands your attorney a case file that would've taken them untold billable hours to assemble.
The architecture, and why I chose it
Why three passes for people, five phases for organizations
The obvious approach: throw everything at one big model call. "Here's a name, research them, give me a profile." Fast to build. But wrong 40% of the time. Wrong-person data mixed with real data. Hallucinated contacts. No source trail. No way to audit what the model found vs. what it invented.
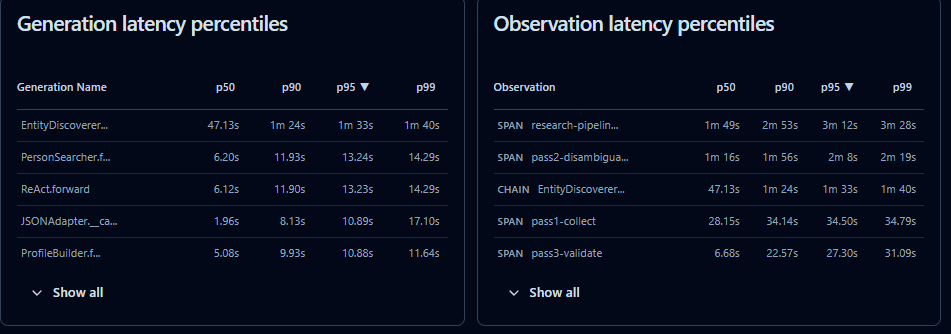
So I split the person pipeline into three passes, each with a different model tier and a different job. A cheap model (Gemini Flash Lite) collects. A reasoning model (Gemini Flash) verifies identity and extracts facts. The same reasoning model synthesizes the final output. Each pass is scoped to exactly what it's good at. You're spending fractions of a cent on collection and reserving the expensive tokens for the work that actually requires reasoning.
The collection pass doesn't analyze anything. It just gathers candidates via web search and scraping, embeds them, and stores them in a vector database. The disambiguation pass gates every document and every high-impact fact through identity verification. The synthesis pass only sees facts that survived verification, and a separate validator cross-checks claims against source text before anything is finalized.
For organizations, the architecture is different because the problem is different. You're not verifying identity, you're mapping structure. The entity pipeline runs five phases in sequence: website crawl, news search, social listen, oversight mapping, and records check. Each phase feeds facts and relationships back into the entity record. The oversight phase is the interesting one. It discovers parent agencies and regulatory bodies, creates stub entity records for them automatically, and links them with typed relationships (oversees, regulates, funds, leases to). The result is a graph you can walk.
Why identity disambiguation is the whole game
This is the part that doesn't come up enough. You search for "Jeff Stewart" and you get results for every Jeff Stewart on the internet. You search for "JCPRD" and you might get the Johnson County Parks & Recreation District in Kansas or something entirely unrelated in another state. If you skip this step, your data is contaminated.
For people, the system builds an identity anchor: a structured object containing the target's known organization, role, state, city, associates, employment history, known events. Every document gets checked against it. Documents that fail don't just get dropped. Their distinguishing traits become negative anchors. The system learns who the target person is not, and carries that forward.
For organizations, I built a parallel system: the entity anchor. It carries the canonical name, known aliases (so "JCPRD" and "Johnson County Park and Recreation District" resolve to the same entity), state, entity type, website domain, and known member names. But here's the key decision: I don't throw every search result at the LLM for verification. That's slow and expensive.
Instead, the system runs a multi-signal pre-filter first. Four independent signals (name similarity, geographic match, website domain match, and member co-occurrence) each produce a 0-to-1 score. Those scores get weighted (name 35%, domain 25%, geography 20%, member co-occurrence 20%) into a composite. Above 0.85: auto-accept, no LLM needed. Below 0.30: auto-reject, no LLM needed. Only the ambiguous middle band hits the reasoning model.
This is meaningful at scale. If 70% of your search results are obvious matches or obvious misses, you just saved 70% of your disambiguation token spend. The LLM only does the work that actually requires judgment.
Confidence tiering is explicit and four-level: confirmed, probable, uncertain, rejected. The thresholds are tunable. Nothing ambiguous makes it into the final output.
Why every LLM call is traced
This is where most AI apps fall apart when you try to debug them. Something's wrong in the output. Which model call produced it? What did the model see? What did it return? Good luck.
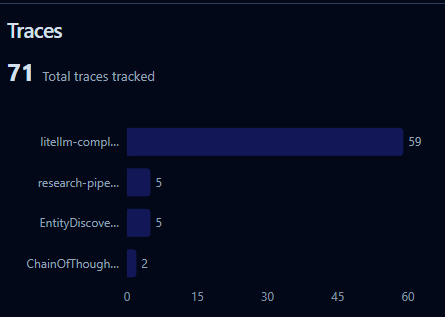
Every LLM call in this system is instrumented through Langfuse . Grouped by research job. Tagged by pipeline phase and model. I can open a trace and see exactly what the collection model searched for, what the disambiguation model accepted or rejected and why, what facts the extractor pulled, and what the synthesizer did with them. If a fact is wrong, I can trace it back to the specific model call that produced it and the specific document it came from.
This isn't monitoring. It's accountability. When your system is making claims about real people and real organizations that could end up in legal proceedings, "it just works, trust me" isn't enough. You need a complete audit trail from source document to final output.
Why model tiering matters
This isn't just about cost. It's about failure modes. A cheap model hallucinating during collection doesn't matter because disambiguation catches it downstream. A reasoning model hallucinating during synthesis matters a lot, which is why validation exists as a separate step.
The architecture is designed around where errors are tolerable and where they aren't.
LiteLLM sits between DSPy and the model providers. DSPy defines typed signatures: structured input/output contracts, not prompt strings. LiteLLM routes to whatever provider is configured. Swapping from Gemini to Anthropic or OpenAI is an env var change. The pipeline doesn't know or care.
Why semantic deduplication instead of URL matching
URL-based deduplication is brittle. The same content lives at different URLs. A school board posts minutes on their site and a news outlet republishes them. URL matching misses that entirely. Semantic deduplication at 0.92 cosine similarity catches it. And since every document gets embedded anyway for search, the marginal cost is zero.
Why graceful degradation instead of hard dependencies
Every external service in this system is optional. Qdrant goes down? Research still runs, you just lose deduplication and semantic search. Redis goes down? Searches still work, just without caching. Langfuse unreachable? No traces, but nothing breaks.
Every service integration initializes lazily, sets an availability flag, and every downstream function checks that flag first. Same pattern everywhere.
This is boring, unsexy engineering. It's also the difference between a demo and a product.
Why human-in-the-loop gates
The system discovers social profiles, organizational members, entity relationships, and enrichment data. None of it goes live automatically. Everything lands as pending. The user confirms or dismisses before any downstream action happens.
Facts have a confidence score and a verified flag. Relationships discovered by the entity pipeline are unverified by default. The system surfaces candidates. The human makes the final call.
The tools and what they actually did
Cursor was my development environment. I made the architectural decisions. Cursor wrote the implementation. Cursor didn't decide to build a three-pass pipeline with identity disambiguation. I did. Cursor didn't design the confidence tiering model, the multi-signal pre-filter, or the entity relationship graph. I did. The AI wrote most of the code. I made the decisions that determine whether the code works when it hits reality.
DSPy is the backbone for all LLM interactions. Typed signatures, ChainOfThought for reasoning, ReAct for tool-using search agents. Structured contracts between your code and the model. When the model's output doesn't match the signature, DSPy handles retry and parsing. Your pipeline code never touches raw strings.
LiteLLM routes all model calls. Provider-agnostic. Model tiering is configuration, not code.
Qdrant on Railway handles the vector layer. Semantic deduplication, document storage, evidence ingestion, cross-entity search. Self-hosted Docker image with a persistent volume.
Redis on Railway for caching. Search results get a 24-hour TTL, keyed by SHA256 hash. API call deduplication. Rate limiting.
Langfuse for full observability. Every LLM call traced end-to-end. Research jobs grouped as traces. Each call tagged by pipeline phase, model name, person/entity ID. OpenInference DSPy instrumentation means every ChainOfThought and ReAct step is captured automatically.
D3.js for the entity relationship graph. Force-directed layout, clickable nodes, typed edges. You can see at a glance who oversees whom, who regulates whom, and navigate directly to any entity's detail page.
FastAPI + Python 3.12 backend. React 19 + Vite + Tailwind frontend on GitHub Pages. BeautifulSoup for scraping. pdfplumber for PDF parsing with Gemini multimodal fallback for scanned documents.
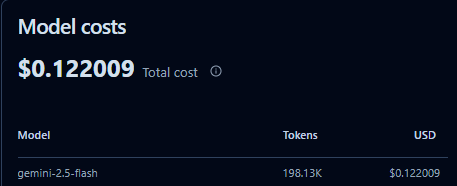
Total hosting costs? Under $100.
Total model costs? I'll let you know - but I can see every penny in LangFuse. I'm using deterministic workflows where appropriate and only invoking AI capabilities where it truly adds value.
Here's a little snapshot.
Why this is more than a Claude subscription
I like Claude. I like ChatGPT. I use them every day. But there's a gap between "ask a model a question and get a response" and "build a system that produces reliable, sourced, auditable output at scale." That gap is architecture.
A single model call doesn't know which Jeff Stewart you're asking about. It can't tell you which source a fact came from. It can't show you why it rejected a document. It doesn't dedupe against what it already knows. It doesn't tier its confidence. It doesn't pause and wait for a human to verify before acting. It doesn't degrade gracefully when an API goes down. And you definitely can't open a trace and audit every decision it made.
These aren't limitations of the models. The models are incredible. These are problems that require systems thinking on top of the models. Identity disambiguation. Confidence scoring. Vector dedupe. Observability. Human gates. Fallback paths. That's not a prompt. That's an architecture.
Claude Code, Cursor, Aider, OpenHands, Devin: they're orchestrators. They help you build this kind of infrastructure. But they don't replace the need for it. Open any of them and say "build me a research platform." You'll get a chatbot that calls an API and prints the result. You will not get a three-pass pipeline with identity disambiguation. You will not get a multi-signal pre-filter that avoids 70% of your LLM spend. You will not get an entity graph that automatically maps regulatory relationships. You will not get four-tier confidence scoring with source attribution. You will not get Langfuse traces that let you audit every decision the system made.
You won't get those things because those aren't code problems. They're architecture problems. And architecture comes from understanding the domain, understanding the failure modes, and making deliberate decisions about every layer of the system.
The hard part of building with AI was never the code. It's knowing what to build and why.
If you're building real systems with AI, I want to hear about it. What does your confidence model look like? Can you trace a wrong answer back to the specific model call that produced it? Where did you put the human in the loop and why? That's the conversation worth having.
.svg)
.svg)
.svg)
Related Blogs







Unlike traditional consultancies, our model is architect-led, fixed-price, and outcome-driven.


Technology That Moves You Forward.
Partner with expert engineers who deliver measurable outcomes.
.svg)
.svg)